I wanted to better understand landownership in Pennsylvania. I am conducting research on a small, rural Black community that is currently known as Six Penny Creek (within French Creek State Park in Union Township, Berks County, PA). The piece of land upon which this community sits was purchased in 1842 by a Black husband and wife by the name of Jehu and Dinah Nixon. It was pretty clear to me that simply purchasing a piece of land was a substantial success for the pair, but I needed data to better demonstrate this. How likely was it for any Black family to purchase land? How did that compare to White families?
Luckily, there’s data available for this through IPUMS. I won’t go all the details about how I got it, etc. – suffice it to say that it is an amazing resource even if it is only accessible to researchers like me. Unfortunately, real estate values were only collected in 1850, 1860 and 1870. At this point, I am most interested in the settlement around the Civil War and so these dates work even if I would have liked to see data from both a little earlier and a little later. That said, these dates still provide important information.
The IPUMS data is coded and therefore amenable to analysis. I downloaded data for Chester County, Pennsylvania. Although Six Penny Creek is in Berks County, the people in the settlement have significant connections to people in Chester County where there are similar small, rural Black communities just across the Maryland border/ Mason-Dixon Line. I included variables such as race (in this case it is coded simply as Black or White), real estate value and relationship to the head of household. The latter is important because almost all land is listed with the head of household (even if it might be owned by a married couple or even a group of individuals). I say “almost all” because sometimes (approximately 10% of the time, regardless of race) someone else in the household is listed as owning real estate.
So, some simple statistics. During this time period, approximately 47-49% of White heads of household did NOT own land while roughly 73-78% of Black heads of household. That’s quite a large difference- more than 50% of White heads of households owned land while only 25% of Black heads of households own land. That alone is a massive difference, but I felt that this did not necessarily paint the full picture. So, I constructed a histogram of the value of the real estate by race and year.
A few notes about the graph below. First, it’s straight from the Pivot Table in Excel and, therefore, some of the labels are outside my control. For example this is divided up by year and race- you can see these labels on the right. Note that “1” is the IPUMS code for White and “2” for Black or African American. There are ways that I could have modified this, but these are not straight forward, but I also think it is important to preserve and consider these codes. What do that say about both historic and present racism? The horizontal axis is “bins” of real estate value in increments of $500. The vertical axis is the percentage of heads of households of that race who owned real estate valued within each “bin”.
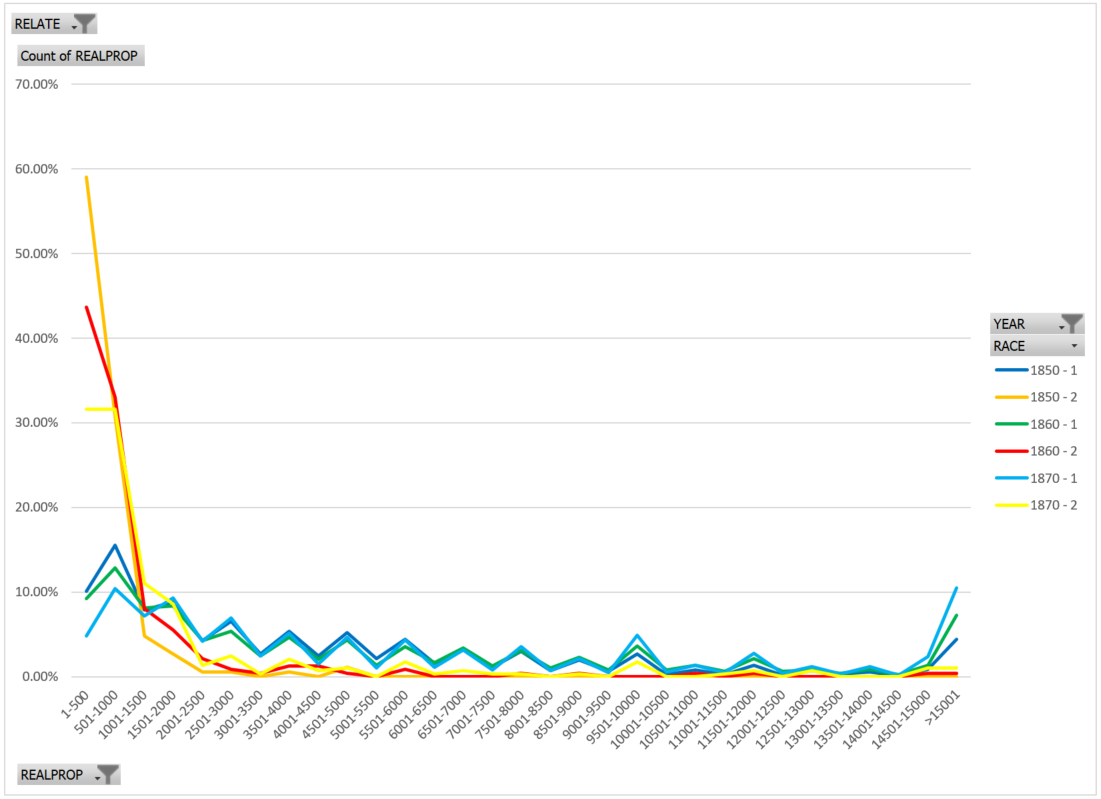
The graph nicely demonstrates how real estate values differ by race. Black heads of household were much more likely to own $1000 or less of real estate (the red/orange and yellow lines). Approximately 80% (1850), 77% (1860), and 60% (1870) of all Black heads of household who owned land were in the lowest two “bins” of value ($1-500 and $501-1000). This is starkly different for White heads of household (blue, green and light blue)- this number hovers around 20% (25% in 1850, 21% in 1860 and 15% in 1870). That is, if Black families were able to acquire land, it was largely low value (likely in terms of both land and homes). While a few Black heads of household were able to own land with a value greater than $1000 these numbers are limited- between $1001-$2500 this is around 8-21% (8% in 1850, 16% in 1860 and 21% in 1870). This means that the majority of Black heads of household who were able to own land were restricted to the lowest valued real estate, but this is not true for White heads of household. In 1850, 97.87% of all Black land-owning heads of household owned less than $2500 worth of real estate, while only 46.62% of all White land-owning heads of household owned less than $2500 worth of real estate. This means that the wealthiest (which also tends to mean the most socially, economically and politically influential group) was almost exclusively white. At the very highest “bin”- 10% of white land- owning heads of household owned real estate valued at more than $15,000, while 1% of Black land owners fell into this range. To get back to numbers, rather than percentages, this means that there were 810 white land-owners in this “bin” but only 3 Black land-owners in 1870.
As a side note, there is clearly some inflation here- the increasing number of land owners (of either race) in the higher bins may just be inflation, but it may also reflect social mobility- something that is hard to tell from this data.
To sum this all up- it was very difficult for Black individuals and families to acquire land. When they were successful, it often meant lower value land. However, even given this situation, some (3) were able to move into that highest “bin.” Although I would be very interested in these individuals, I would also suggest that being Black and owning any land, no matter how valuable, was quite a feat. On the flip side, this certainly does not mean that those Black folks who were unable to own land did anything wrong. Given the dire racism of the time (recall that Black men had the right to vote in PA up until the state constitution was rewritten in 1837/8), not owning land might simply have to do with not being in the right place at the right time.
We know that Jehu Nixon was a forgeman for the Potts family, well-known iron moguls and abolitionists. It is likely that he was able to purchase the land both because of his profession and because of his connection to a VERY wealthy family. Not all Black folks could claim such connections- indeed many were coming into the area directly from enslavement in the south. Jehu Nixon was born a free man in Pennsylvania (actually, he might have been born into slavery in PA, but I haven’t been able to prove that yet).
What is remarkable is that Jehu and Dinah, over the next few years, sold portions of their land to other Black families creating a small, rural Black community (at it’s peak it was around 10 houses and 45 people) well known for their connection to the Underground Railroad.